TensorRT는 학습된 Deep Learning 모델을 최적화하여 NVIDIA GPU상에서 Inference 속도를 향상시켜 Deep Learning 서비스를 개선하는데 도움을 줄 수 있는 모델 최적화 엔진이다.
다양한 Deep Learning Framework를 통해 작성된 Model을 TensorRT를 이용하여 최적화하여 NVIDIA Gpu 환경에 적용가능하도록 할 수 있다.

TensorRT를 통해 얻을 수 있는 당연히 Inference 가속을 통한 속도 향상이다.
ResNet50을 기준으로 할 때 동일한 Gpu에서 TensorRT를 사용하는 것만으로도 8배 이상의 성능 효과가 있는 것을 알 수 있습니다. OS에 따라 성능차이는 있을 수 있다. 또한 Linux에서는 C++ 및 Python Api를 제고하는 반면 2020년 8월 기준으로 Windows에서는 C++ Api만을 제공한다.
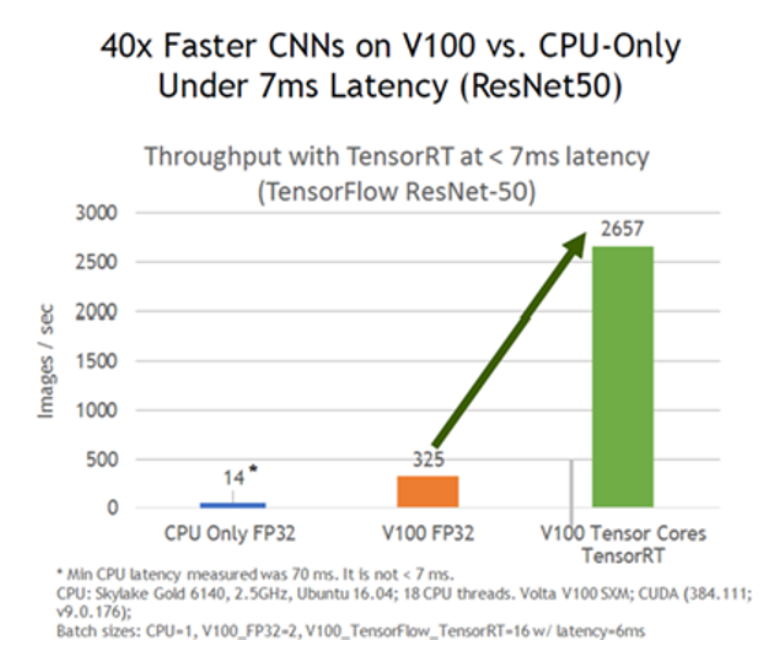
자세한 성능 비교는 아래 URL을 참고하기 바란다.
속도 향상을 위해 TensorRT에서 사용하는 대표적인 기법들에 대해 간략하게 정리하겠다.

Quantization & Precision Calibration
Deep Learning Training(학습) 및 Inference(추론)에서 Precision reduction(정밀도 절감)은 일방적인 방법이다.
왜냐하면 낮은 Precision의 Model일 수록 data의 크기 및 Weights(가중치)의 bit수가 작으므로 빠른 연산이 가능하기 때문이다.
이를 위해 TensorRT는 Symmetric Linear Quantization을 사용여 일반적인 FP32의 data를 FP16 및 INT8의 data type으로 precision을 낮추는 것을 제공한다.
Symmetric Linear Quantization은 아래 그림을 참고 하기 바란다.

일반적으로 FP16의 data type으로 precision을 낮추는 것은 기존 Model의 Accuracy(정확도)를 에 큰 영향을 주지 않지만 INT8의 data type의 경우 기존 Model의 Accuracy에 영향을 미치므로 Calibarion 과정이 필요하다.
TensorRT에서는 3가지 Calibration 방법을 제공한다.
1. EntronpyCalibrator
2. EntropyCalibrator2
3. MinMaxCalibrator
Calibration을 통해 quantization 시 weights 및 tensor들의 정보 손실을 최소화 할 수 있다.

Graph Optimization
일반적으로 Graph Optimization은 graph node들을 각 platform에 최적화된 Code로 구성하기 위해 사용된다.
TensorRT는 이를 기반으로 Layer Fusion 방식과 Tensor Fusion 방식을 지원한다.
Vertical, Horizontal의 Node들을 합성하여 단순화 시킨 것을 확인 할 수 있다.
이를 통해 Optimization 된 graph는 layer 갯수가 감소 된는 것을 확인 할 수 있다.

Kernel Auto-tuning
TensorRT는 NVIDIA의 다양한 platform 및 architecture에 맞는 Runtime 생성을 도와준다.
각 platform 및 architecture는 CUDA engine 갯수, memory등 서로 다른 환경으로 구성되어 있으므로 이에 맞는 engine binary 생성을 지원한다.
Dynamic Tensor Memory
Memory management를 통해 memory 재사용율을 높이는 기능이다.
Multi-stream execution
CUDA stream 기술을 이용하여 multiple input stream의 scheduling을 통해 병렬 효율을 극대화하는 기능이다.
정리하자면 TensorRT 사용방법은 아래그림과 같이 정리할 수 있다.

1. 사용하는 Framework를 통해 Model 설계하고 학습을 진행한다.
2. TensorRT를 통해 Model의 Optimization을 진행한다.
3. TensorRT Runtime을 통해 NVIDIA의 다양한 Platform에서 최적의 서비스 제공에 이용한다.
참고 자료 1 : https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html
Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
To optimize your model for inference, TensorRT takes your network definition, performs optimizations including platform-specific optimizations, and generates the inference engine. This process is referred to as the build phase. The build phase can take con
docs.nvidia.com
참고 자료 2 : https://blogs.nvidia.co.kr/2020/02/19/nvidia-tensor-rt/
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit - 엔비디아 공식 블로그
엔비디아 텐서(Tensor)RT는 다양한 딥 러닝 프레임워크로 사전 트레이닝된 뉴럴 네트워크들이 엔비디아 GPU 플랫폼에서 효과적으로 추론을 할 수 있게 돕는 툴 킷 혹은 라이브러리입니다. 텐서 RT의
blogs.nvidia.co.kr
'Deep Learning' 카테고리의 다른 글
| fit() vs fit_generator in keras (0) | 2024.02.27 |
|---|---|
| CONNX (0) | 2022.10.04 |
| ONNX (0) | 2022.08.31 |
| Browse State-of-the-Art (SOTA) (0) | 2020.08.11 |
| bias-variance tradeoff (0) | 2020.07.14 |
